Can AI Put an End to Big Data’s Boulevard of Broken Dreams?

Big data came with big promises left largely unfulfilled. But advancements in AI and AI-era data platforms may be the key to finally unlocking its value.

Big data came with big promises left largely unfulfilled. But advancements in AI and AI-era data platforms may be the key to finally unlocking its value.

These takeaways will help you streamline your rollout of Einstein Copilot, our new conversational AI assistant for CRM.

We answer some basic questions about what Salesforce does, what Salesforce CRM software is used for, and how Salesforce works.

The best way to make sure your AI implementation is strategic and effective is to have clear business goals, and to ask the right questions.

They’re global and super tech savvy. But that’s not all. We spoke with two leading researchers about the nuances of connecting with this new generation.

How to take generative AI prompts to the next level with retrieval augmented generation, or RAG.

Get insights, and streamline processes with the latest Sales trends, insights, and conversations.
See All Stories
Read actionable advice from leading sales influencers as they focus on growth in the year ahead.

Perfect your sales calls using these sought-after tips from sales experts.


What can a customer data platform do for your brand? Learn how it can bring you closer to your customers — with help from AI.

Here are five industry-specific examples of how an AI copilot can make your work life easier.

Generative AI is laying the foundation for a new kind of app: super intelligent assistants that can do the work of hundreds — or even thousands — of individual applications based on a simple prompt.

Global data will double every 12 hours by 2025. This glossary of data terms will help everyone in your company understand the power of real-time, actionable data in the age of generative AI.
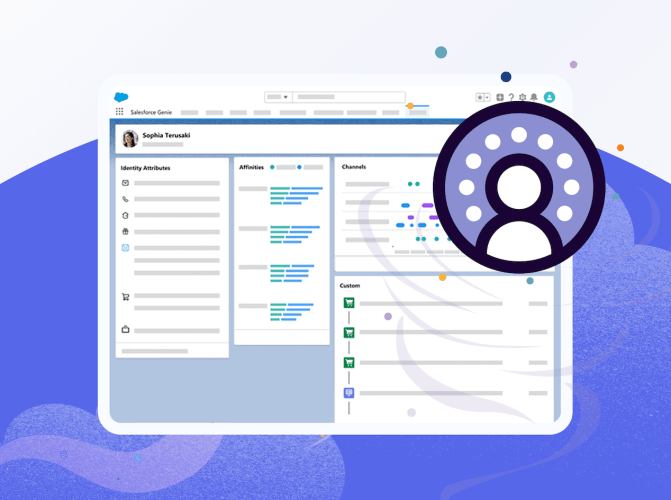
Unlock trapped data with Data Cloud, the only data platform native to the world’s #1 AI CRM.
Stay ahead in the game with the latest cutting-edge trends and expert tips, where innovation meets customer satisfaction.
See All Stories
Turn customer interactions into insights that help your business improve with service intelligence.

Some service leaders swear by Net Promoter Score, while others think it’s obsolete. We asked our Trailblazer community to weigh in. Here’s what they told us.


Get the latest articles in your inbox.
















